Problem
A tool using machine learning was created to aid an M&A buyer more easily match large repositories of files with their due diligence checklist. During a beta period, a series of challenges arose both from user feedback and as improvements to the AI model were being made.
- Analytics revealed that users were manually matching documents to their checklists instead of using the provided AI tools.
- A recent improvement to the model required at least some matching of documents in order to significantly boost accuracy.
Discovery
We conducted a series of interviews to better understand the user behavior we were observing the analytics. These revealed a general sense of distrust, especially around why certain documents were being pushed forward by the model. Additionally, we observed that the AI matching tool was outside of a user’s expected flow for matching documents, so users often ignored or missed AI matching.
This provided us the necessary problem statements to run design workshops with the team and stakeholders.
Solution
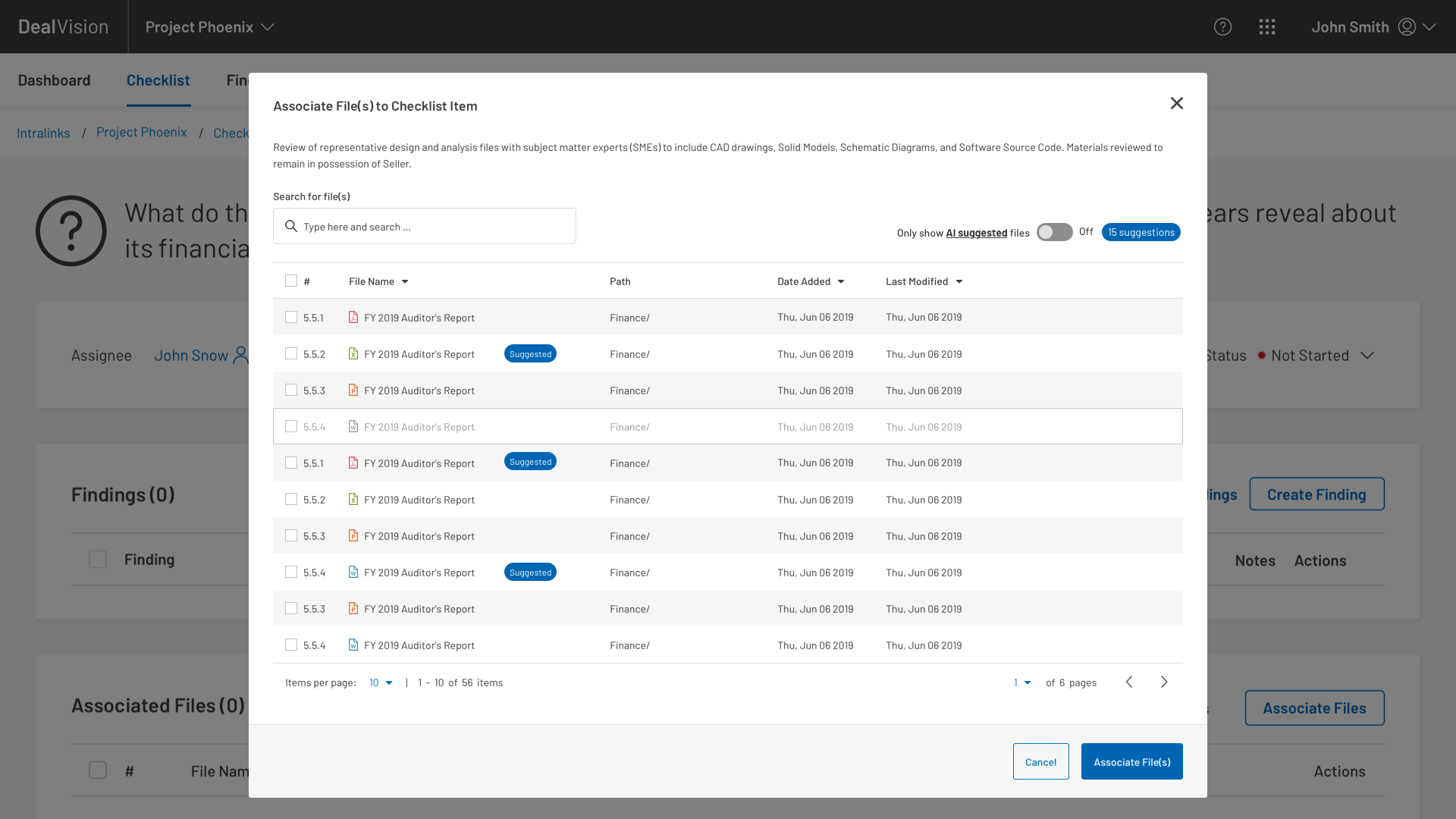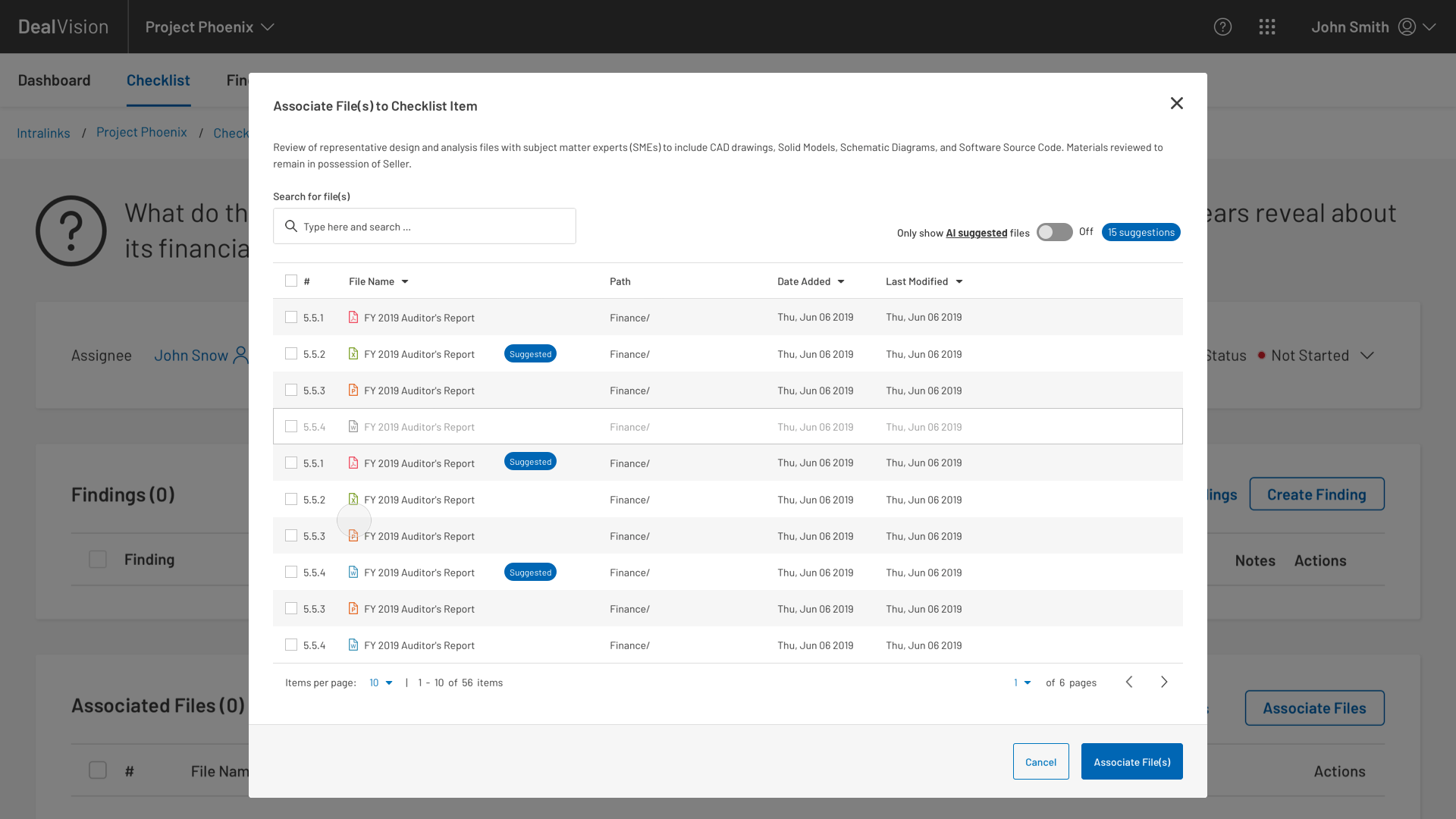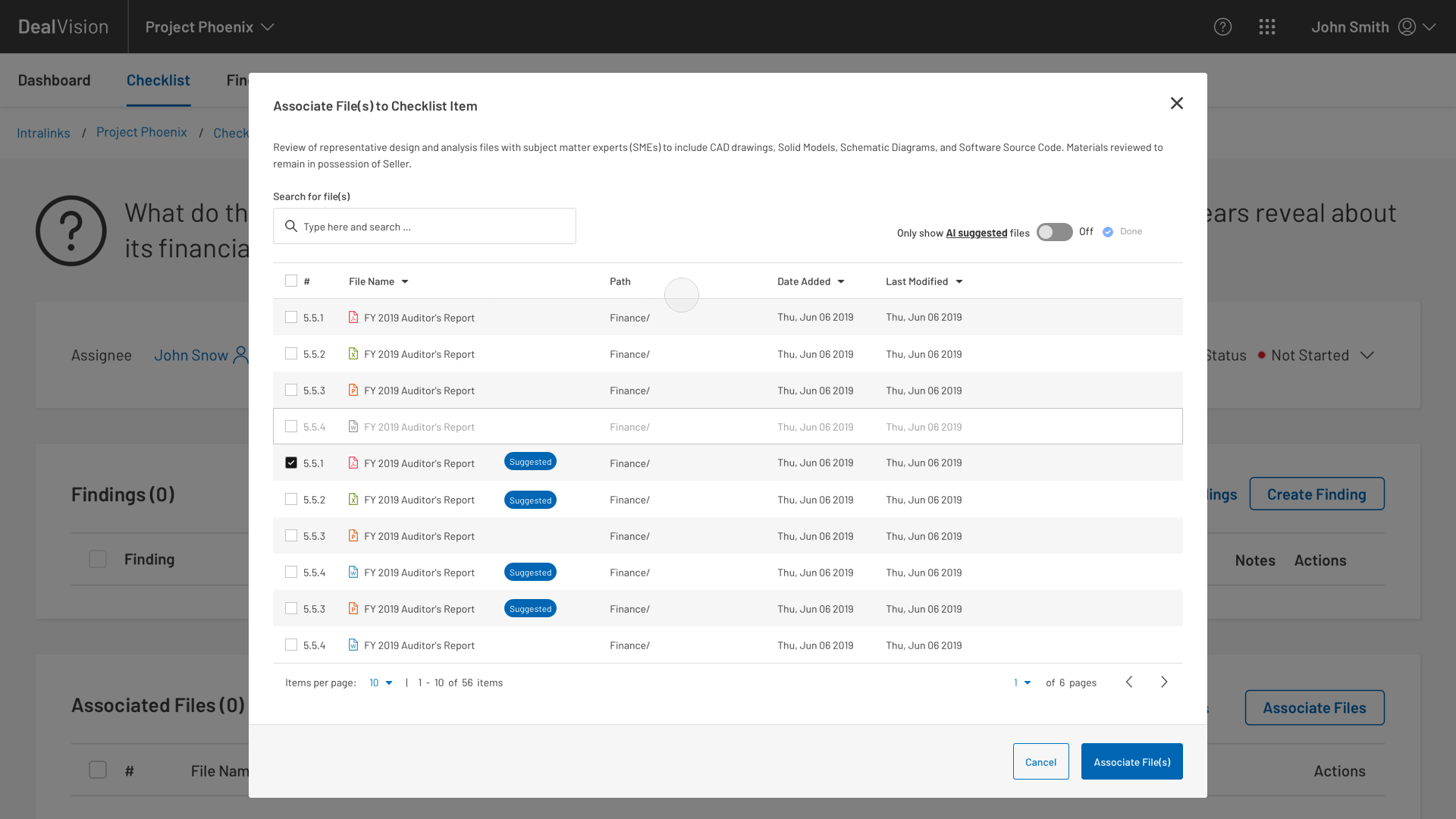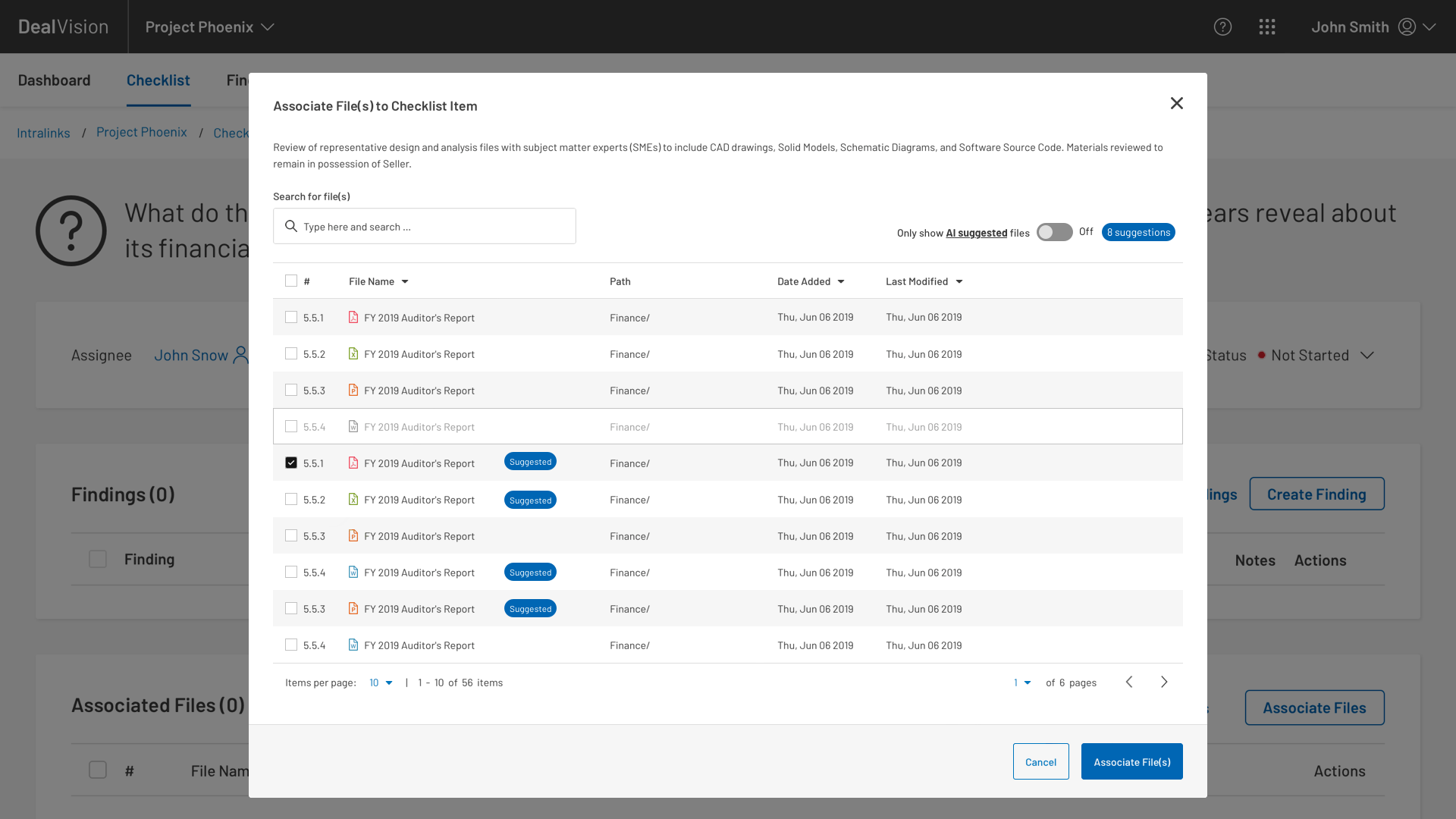
Having been brought on board to support the AI teams, my first step was to collaborate with the lead designers on the buy-side tool. Our task was to rethink the document matching flows so that the AI portion was integrated into the primary task of matching documents. When these flows were merged, an opportunity revealed itself to us that would enable the UI to adjust which AI-matched documents were presented to the user based on their most recent selections.
In addition to the UI and information architecture, we softened the language around AI components to show a little more humility given the low levels of trust observed in the discovery interviews.
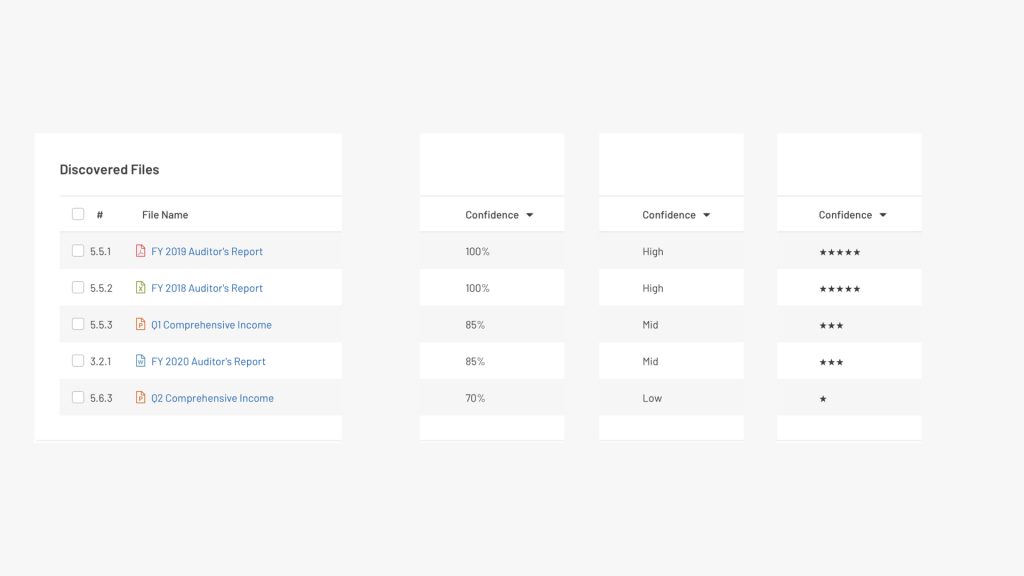
Low trust issues with the AI portion of the app were further addressed with an experiment to test several versions of a “confidence score” displayed next to AI-suggested documents. Similarly, we also tested a “confidence score throttle” to see how many suggestions users would tolerate.
Results
Once the flows were merged, we saw a significant uptick in document associations and training interactions for the AI model. We also observed an increase in new feature requests from our users, paired with a decrease in negative feedback around common task flows. We took this as one signal that customers weren’t being bogged down with inefficient primary tasks.
For the confidence score experiments, we made a couple of important observations:
- Explaining how the model worked ended up creating more questions than answers for our users.
- Participants preferred a pretty consistent “confidence score throttle”, which allowed us to remove the control and set the throttle behind the scenes.
When testing the display of confidence scores, two personas were revealed to us:
- Users who wanted quantitative certainty.
- Users who were comfortable with ambiguity.
To that end, we decided that softening the language, merging the task flows, and simplifying the confidence score to a binary indicator gave us the most return on the experience. In other words, we decided to do less in order to get more.